

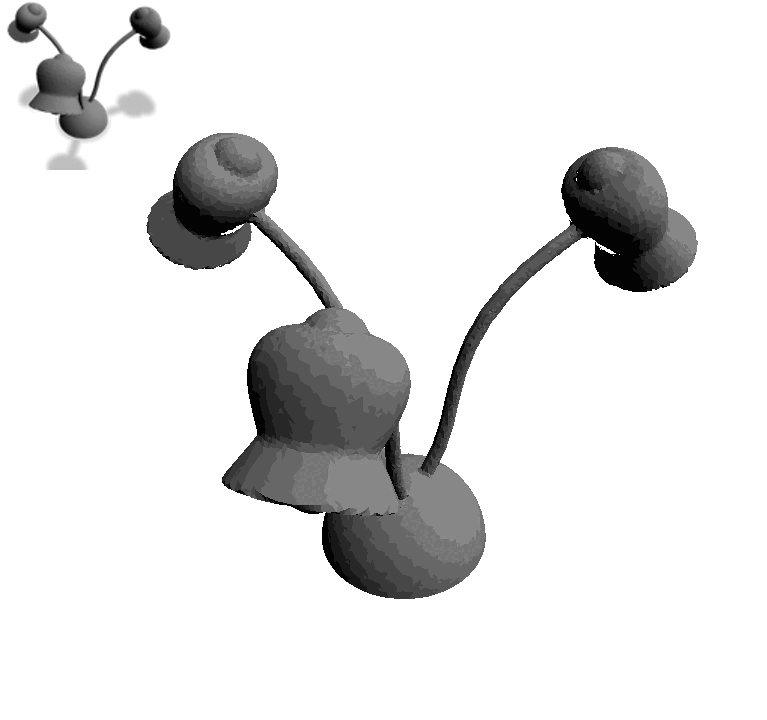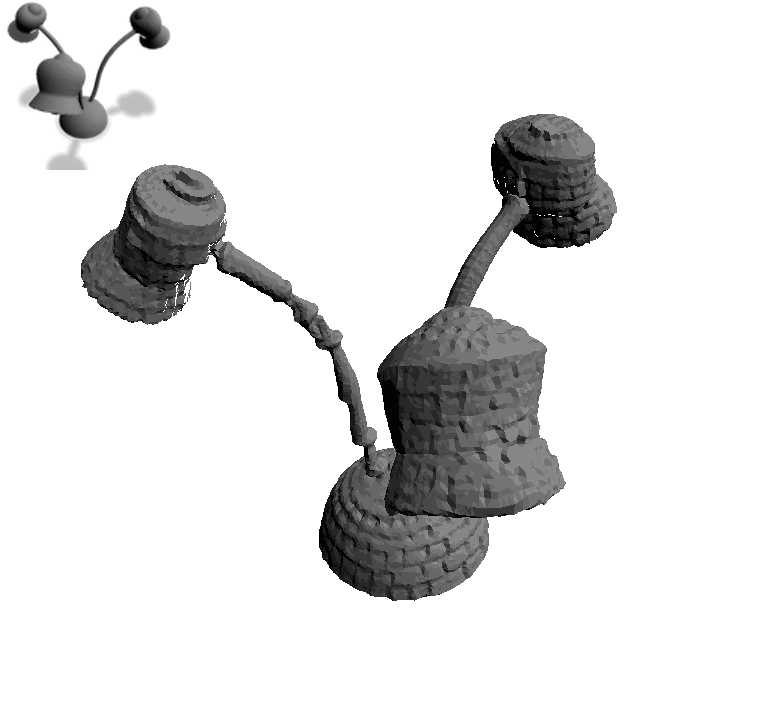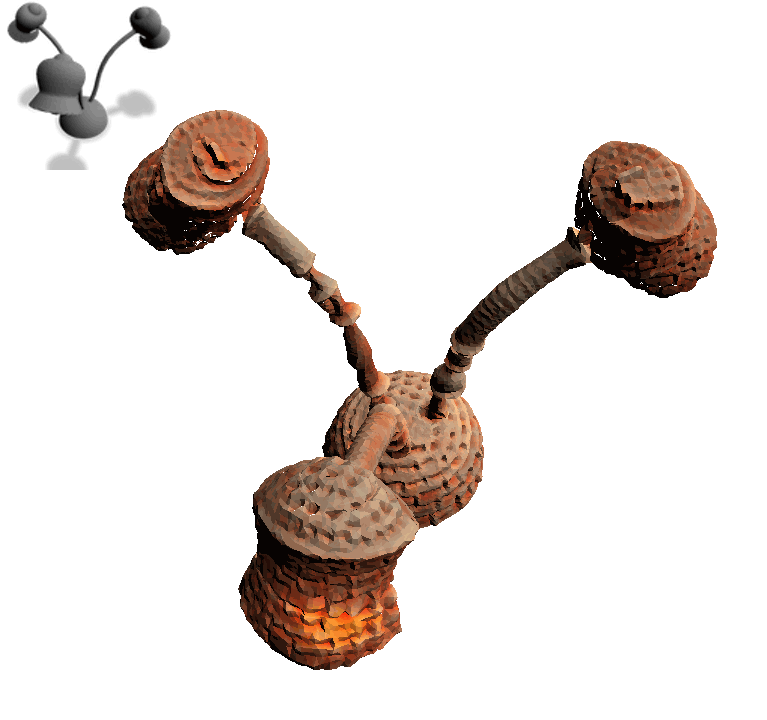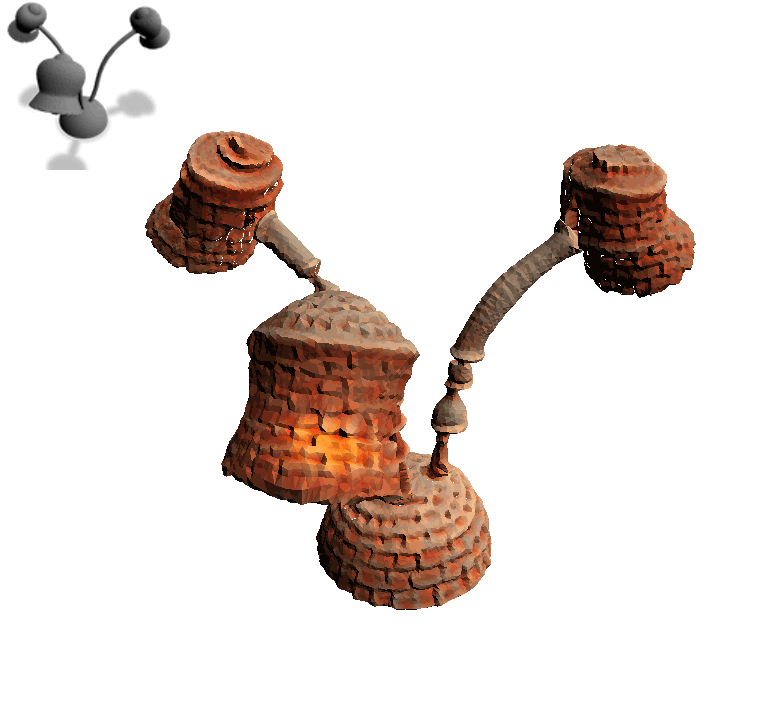
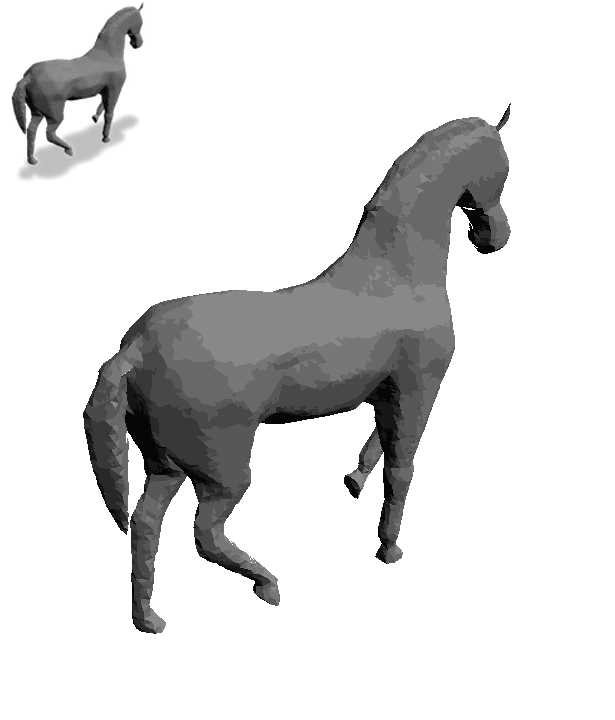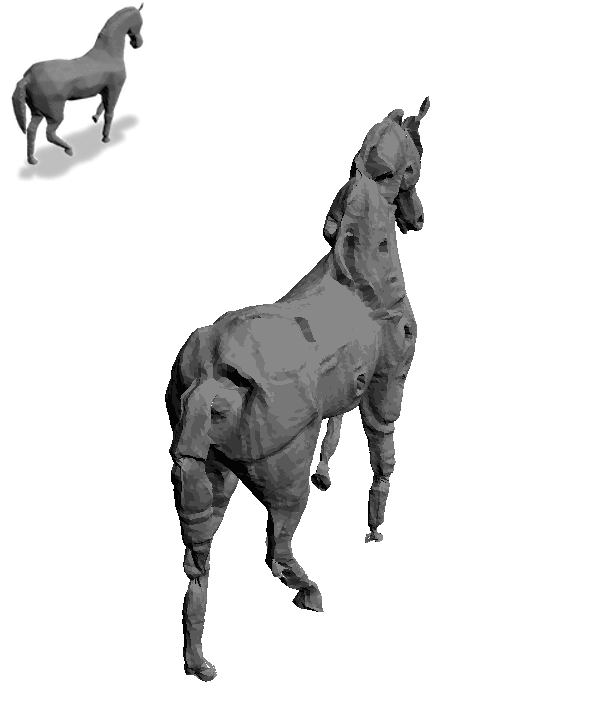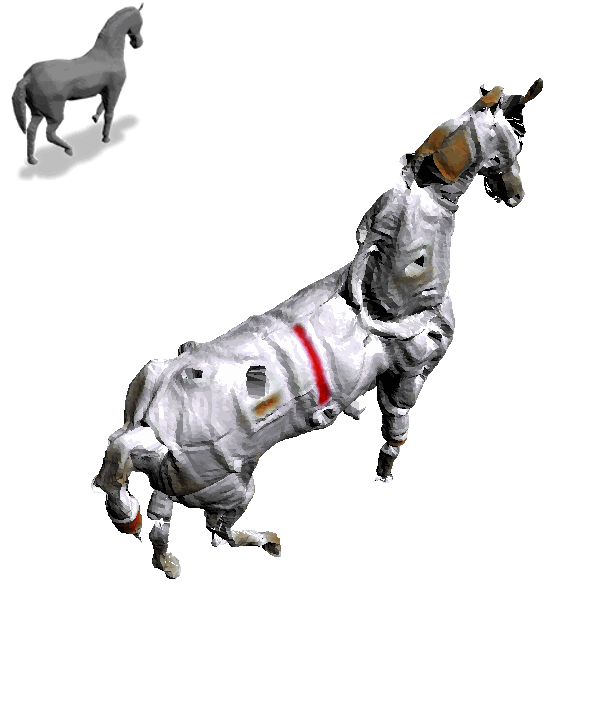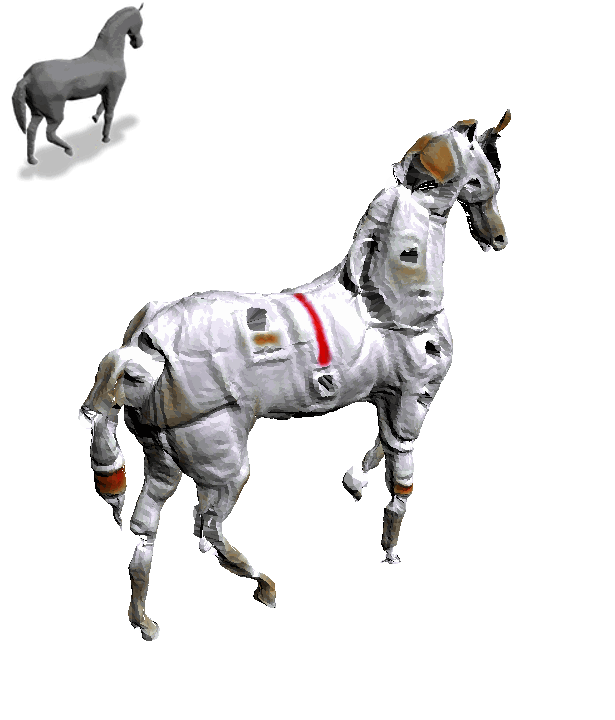
Text2Mesh produces color and geometric details over a variety of source meshes, driven by a target text prompt. Our stylization results coherently blend unique and ostensibly unrelated combinations of text, capturing both global semantics and part-aware attributes.
Code Paper SupplementaryAbstract
In this work, we develop intuitive controls for editing the style of 3D objects. Our framework, Text2Mesh, stylizes a 3D mesh by predicting color and local geometric details which conform to a target text prompt. We consider a disentangled representation of a 3D object using a fixed mesh input (content) coupled with a learned neural network, which we term neural style field network. In order to modify style, we obtain a similarity score between a text prompt (describing style) and a stylized mesh by harnessing the representational power of CLIP. Text2Mesh requires neither a pre-trained generative model nor a specialized 3D mesh dataset. It can handle low-quality meshes (non-manifold, boundaries, etc.) with arbitrary genus, and does not require UV parameterization. We demonstrate the ability of our technique to synthesize a myriad of styles over a wide variety of 3D meshes.
Overview
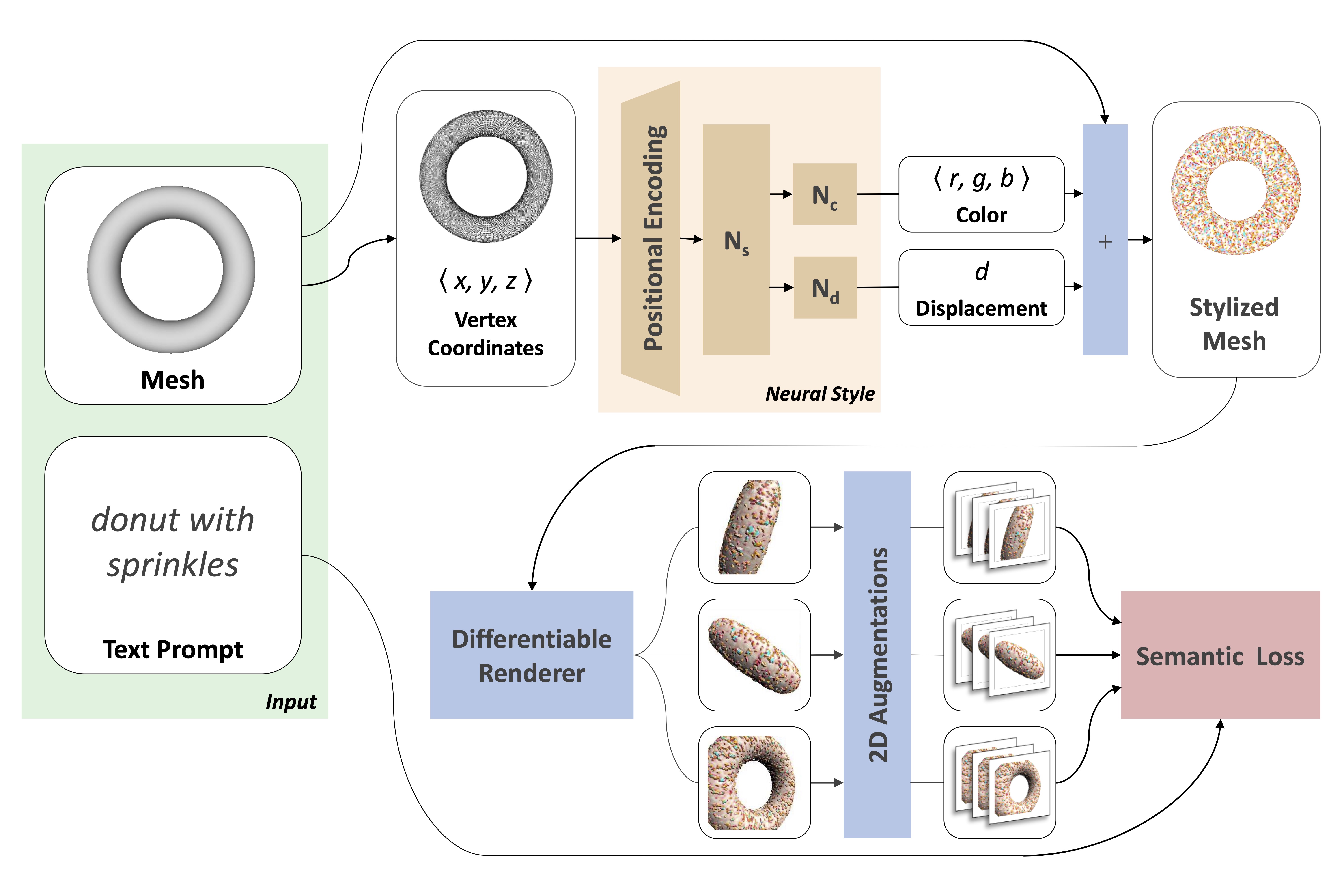
Text2Mesh modifies an input mesh to conform to the target text by predicting color and geometric details. The weights of the neural style network are optimized by rendering multiple 2D images and applying 2D augmentations, which are given a similarity score to the target from the CLIP-based semantic loss.
View Consistency
We use CLIP’s ability to jointly embed text and images to produce view-consistent and semantically meaningful stylizations over the entire 3D shape.
General Stylization
For the same input mesh, Text2Mesh is capable of generating a variety of different local geometric displacements to synthesize a wide range of styles.
Ablations
We show the distinct effect of each of our design choices on the quality of the final stylization through a series of ablations.
Ablation on the priors used in our method (full) for a candle mesh and target ‘Candle made of bark’: w/o our style field network (−net), w/o 2D augmentations (−aug), w/o positional encoding (−FFN), w/o crop augmentations for ψlocal (−crop), w/o the geometry-only component of Lsim (−displ), and learning over a 2D plane in 3D space (−3D).
Text Specificity
We are able to synthesize styles of increasing specificity while retaining the details from the previous levels.
made of crochet
made of crochet
iron made of crochet
with corrugated metal
Beyond Text-Driven Manipulation
We further leverage the joint vision-language embedding space to demonstrate the multi-modal stylization capabilities of our method.
Image and Mesh Targets
Citation
@article{text2mesh,
author = {Michel, Oscar
and Bar-On, Roi
and Liu, Richard
and Benaim, Sagie
and Hanocka, Rana
},
title = {Text2Mesh: Text-Driven Neural Stylization for Meshes},
journal = {arXiv preprint arXiv:2112.03221},
year = {2021}
}