Bamboo Chair
Tiger Playing Chess
Michelangelo Statue of Lion
Robot Elephant
Michelangelo Statue of Bird
Michelangelo Statue of cat
Rabbit Drinking Coffee
Squirrel Drinking Coffee
Frog Reading Newspaper
We introduce HyperFields, a method for generating text-conditioned NeRFs with a single forward pass or with some finetuning. Key to our approach is (i) a dynamic hypernetwork, which learns a smooth mapping from text token embeddings to the space of neural radiance fields; (ii) NeRF distillation training in which we distill scenes encoded in individual NeRFs into one dynamic hypernetwork. We demonstrate that through the above techniques, the network is able to fit over a hundred unique scenes. We further demonstrate that HyperFields learns a more general map between text and NeRFs, and consquently is capable of predicting novel in-distribution and out-of-distribution scenes either zero-shot or with a few finetuning steps. HyperFields finetuning benefits from accelerated convergence thanks to the learned general map, and is capable of synthesizing novel scenes 5 to 10 times faster than existing neural-optimization based methods. We finally demonstrate that the learned representation is smooth, through smooth interpolation of text latents across different NeRF scenes.
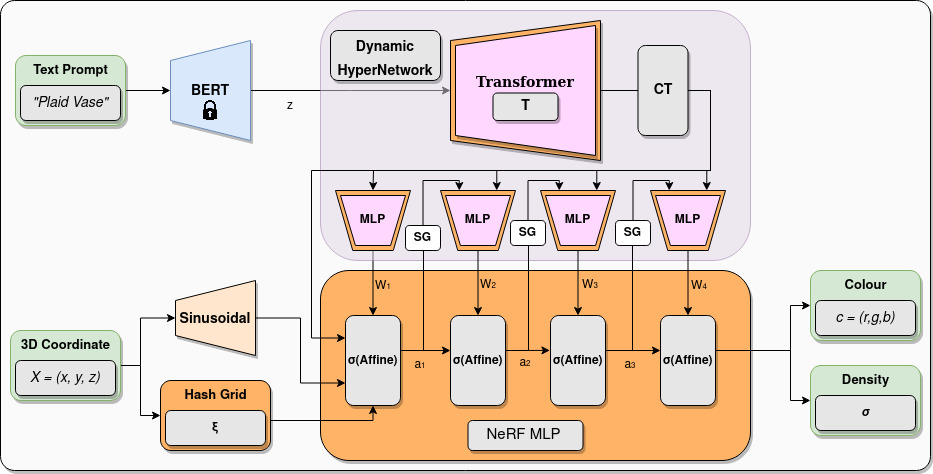
The input to the HyperFields system is a text prompt, which is encoded into latents by a pre-trained text encoder, which in our case is a frozen BERT model. The text latents are passed to a Transformer module, which outputs a conditioning token (CT).
This conditioning token (which supplies scene information) is used to condition each of the MLP modules in the hypernetwork. The first hypernetwork MLP (on the left) predicts the weights W1 of the first layer of the NeRF MLP, which is the standard NeRF neural architecture that actually encodes and synthesizes the desired scene. The second hypernetwork MLP then takes as input both the CT as well as a1, which are the activations from the first predicted NeRF MLP layer, and predicts the weights W2 of the second NeRF MLP.
The subsequent scene-conditioned hypernetwork MLPs follow the same pattern, taking the activations ai−1 from the previous predicted NeRF MLP layer as input to generate weights Wi for the ith layer of the NeRF MLP. We also introduce stop gradients (SG) during hypernetwork training so that gradients are not backpropoagated through the activations of the predicted NeRF layers. The dynamic hypernetwork system allows our model to dynamically update for a given scene input (text prompt) and 3D coordinate input processed by the NeRF MLP
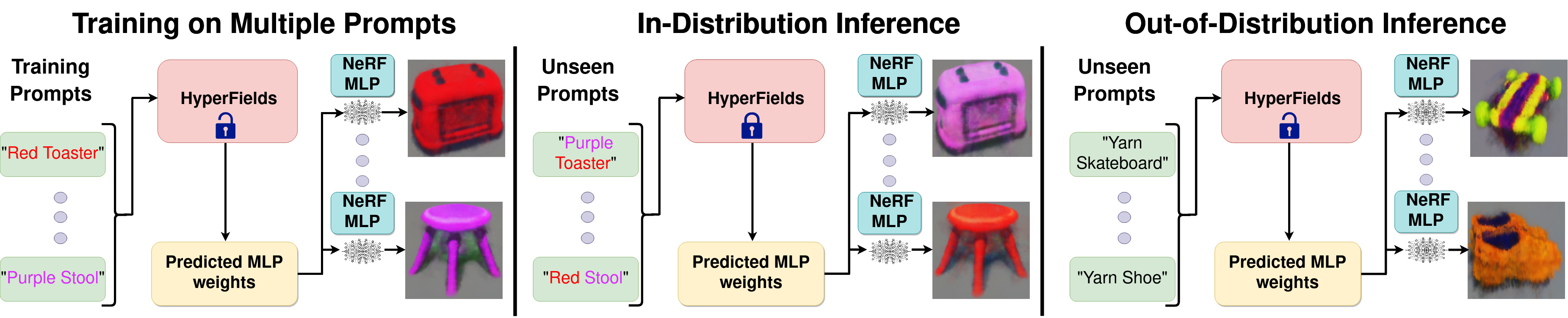
Our method is able to train on a subset of the colour-shape combinations, and during inference predict the unseen colour-shape scenes zero-shot, without any test time optimization. We call this in-distribution generalization as both the shape and the color are seen during training but the inference time scenes (opaque scenes in the figure below) are still novel because the combination of color and shape is unseen during training. Example: “Orange toaster” is a prompt the model has not scene during training, however it has seen the color “orange” and the shape “toaster” its training set. Hence “orange toaster” is an in-distribution novel scene.

Faded objects are the results of HyperFields on prompts used during training, and opaque objects are results on unseen prompts. Note that all results are obtained in a single feedforward manner (i.e. no test time optimization). All types of shapes and colors are seen during training, however during inference we present novel unseen combinations.
We train our model on a rich source of prompts, across multiple semantic dimensions (material, appearance, shape). The list of prompts used is provided in the supple- mental material section 9.
Post training, we test our model on prompts shown in the below figure. The prompts are grouped based on whether the shape is unseen (column 1, below figure) or both shape and attribute are unseen (column 2, below figure). Since either the attribute or the shape is unseen during training we term this as out-of-distribution prompts. Example, in “gold blender” both material “gold” and “blender” is unseen during training

Our method generates scenes that capture the given out-of-distribution prompt in at most 2k steps (row 1), whereas baseline models are far from the desired scene at the same number of steps (row 2 and 4). When allowed to fine-tune for longer (row 3 and 5) the quality of baseline’s generations are worse or at best comparable to our model’s generations despite our model being fine tuned for significantly fewer steps. Demonstrating our model’s ability to adapt better to unseen shapes and attributes.
@inproceedings{babuhyperfields,
title={HyperFields: Towards Zero-Shot Generation of NeRFs from Text},
author={Babu, Sudarshan and Liu, Richard and Zhou, Avery and Maire, Michael and Shakhnarovich, Greg and Hanocka, Rana},
booktitle={Forty-first International Conference on Machine Learning}
}