Target text: "a bust of Albert Einstein"
TextDeformer produces both global semantic changes and local detailing on an input mesh, driven by a target text prompt. Our method produces higher quality surfaces than previous, vertex-based methods.
Code PaperAbstract
We present a technique for automatically producing a deformation of an input triangle mesh, guided solely by a text prompt. Our framework is capable of deformations that produce both large, low-frequency shape changes, and small high-frequency details. Our framework relies on differentiable rendering to connect geometry to powerful pre-trained image encoders, such as CLIP and DINO. Notably, updating mesh geometry by taking gradient steps through differentiable rendering is notoriously challenging, commonly resulting in deformed meshes with significant artifacts. These difficulties are amplified by noisy and inconsistent gradients from CLIP. To overcome this limitation, we opt to represent our mesh deformation through Jacobians, which updates deformations in a global, smooth manner (rather than locally-sub-optimal steps). Our key observation is that Jacobians are a representation that favors smoother, large deformations, leading to a global relation between vertices and pixels, and avoiding localized noisy gradients. Additionally, to ensure the resulting shape is coherent from all 3D viewpoints, we encourage the deep features computed on the 2D encoding of the rendering to be consistent for a given vertex from all viewpoints. We demonstrate that our method is capable of smoothly-deforming a wide variety of source mesh and target text prompts, achieving both large modifications to, e.g., body proportions of animals, as well as adding fine semantic details, such as shoe laces on an army boot and fine details of a face.
Overview
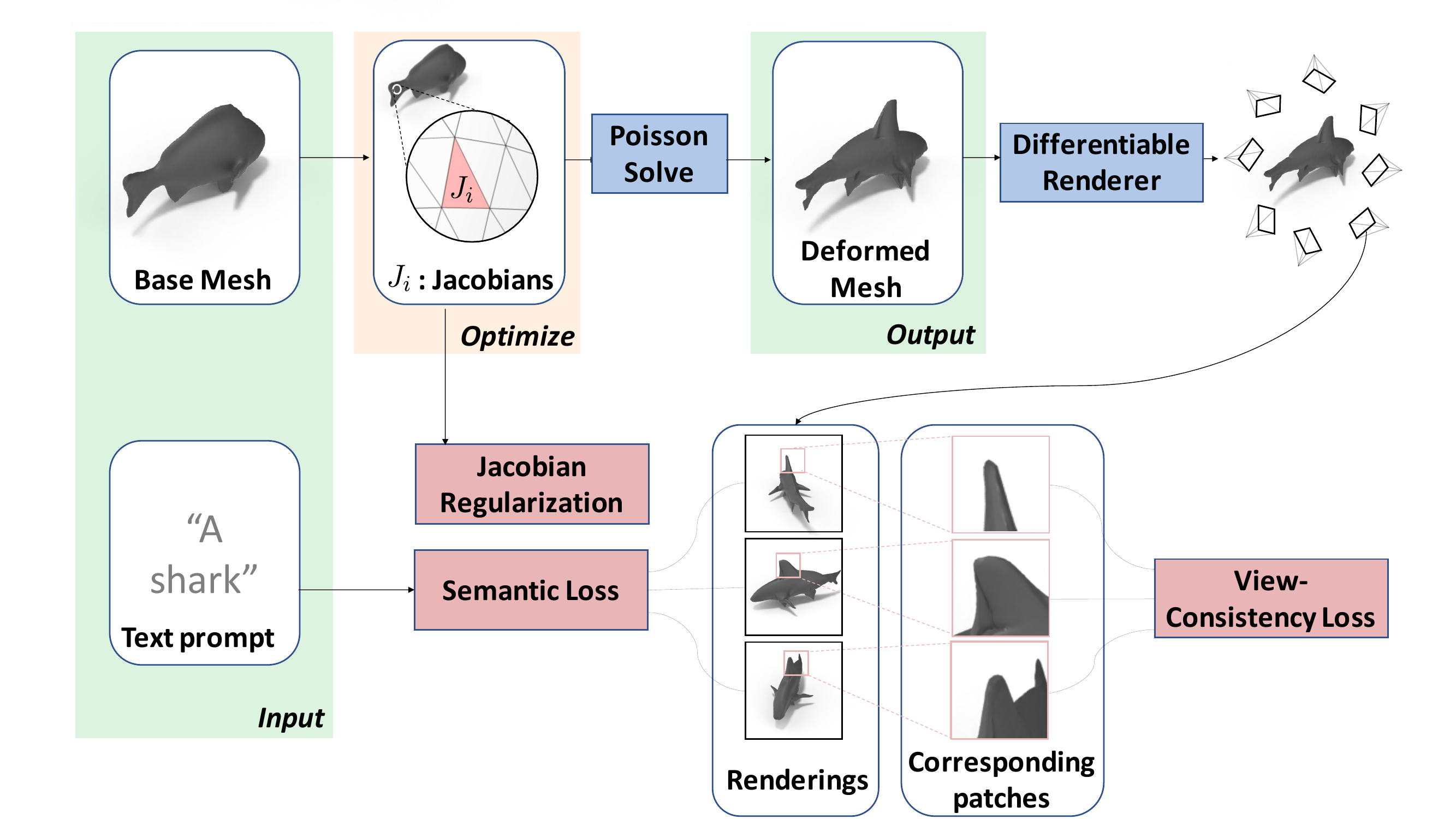
TextDeformer deforms a base mesh by optimizing per-triangle Jacobians using natural language as a guide. We optimize the deformation using three losses: a CLIP-based semantic loss drives the deformation toward the text prompt, a view-consistency loss matches multiple views of the same surface patch to ensure a coherent deformation, and our regularization on the Jacobians controls the fidelity to the base mesh
Results
| Source | Deformed | Optimization process |
|
|
|
|
| Target text: "a camel" | ||
|
|
|
|
| Target text: "a giraffe" | ||
|
|
|
|
| Target text: "a ladybug" | ||
|
|
|
|
| Target text: "an octopus" | ||
|
|
|
|
| Target text: "a submarine" | ||
|
|
|
|
| Target text: "a heart shaped vase" | ||
|
|
|
|
| Target text: "a royal goblet" | ||
|
|
|
|
| Target text: "a mandolin" | ||
|
|
|
|
| Target text: "a bust of venus" | ||
Citation
@InProceedings{Gao_2023_SIGGRAPH,
author = {Gao, William and Aigerman, Noam and Groueix Thibault and Kim, Vladimir and Hanocka, Rana},
title = {TextDeformer: Geometry Manipulation using Text Guidance},
booktitle = {ACM Transactions on Graphics (SIGGRAPH)},
year = {2023},
}