Abstract
The gradual nature of a diffusion process that synthesizes samples in small increments constitutes a key ingredient of Denoising Diffusion Probabilistic Models (DDPM), which have presented unprecedented quality in image synthesis and has been recently explored in the motion domain. In this work, we propose to adapt the gradual diffusion concept (operating along a diffusion time-axis) into the temporal-axis of the motion sequence. Our key idea is to extend the DDPM framework to support temporally varying denoising, thereby entangling the two axes. Using our special formulation, we itera- tively denoise a motion buffer that contains a set of increasingly-noised poses, which auto-regressively produces an arbitrarily long stream of frames. With a stationary diffusion time-axis, in each diffusion step we increment only the temporal-axis of the motion such that the framework produces a new, clean frame which is removed from the beginning of the buffer, followed by a newly drawn noise vector that is appended to it. This new mechanism paves the way toward a new framework for long-term motion synthesis with applications to character animation and other domains.
Key Idea
We entangle the time-axis of diffusion and the temporal-axis of motion, resulting in a motion buffer which encodes noisy predictions of future frames.
Training
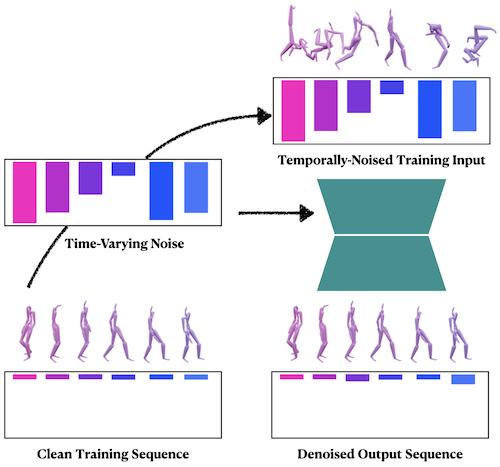
We train our diffusion-based model to remove temporally-varying noise that is applied to clean sequences during training. In each iteration, we fetch a motion sequence from the dataset, apply noise to it according to a noise level schedule, and train our network to predict the clean motion sequence in a supervised fashion.
Inference
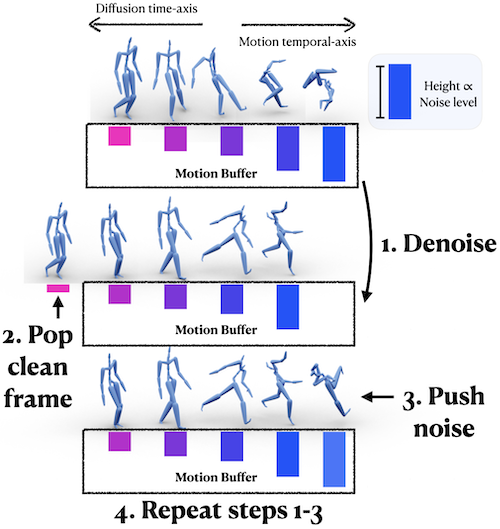
Our method is capable of generating an arbitrarily long motion sequence. First, we initialize our motion buffer with a set of increasingly-noised motion frames. Then (step 1) we denoise the entire motion buffer, (step 2) pop the new, clean frame at the beginning of the motion buffer, and then (step 3) push noise into the end of the motion buffer. This process is repeated recursively.
Long-Term Generation
Our method synthesizes arbitrarily long motion sequences.
Gallery
Our framwork generates diverse motion sequences with the same model.
Wandering around
Zombie walk
Sidesteps
Variation
Due to the stochastic nature of diffusion models, our method is able to generate variations using the same motion primer as input. We show four motions generated from a single primer, from left to right, we can see that the motions begin to differ significantly as time goes on.
Guided Generation
Given a set of motion guides (shown in yellow), we are able to perform them in sequence at desired points while generating plausible motion in the interactively generated frames (blue). Our method generates an entire motion sequence that contains the desired motion guides and the interactively synthesized motion. The interactively generated motions will “prepare and plan” for the upcoming motion guides.
Trajectory Control
Our work can be applied to perform trajectory control during inference without additional training. Similar to the mechanism of guided generation, trajectory control is achieved with inpainting in the motion buffer. Namely, during inference, we recursively overwrite the trjactory information in the motion buffer with frames in the desired trajectory.
Acknowledgements
We thank the 3DL lab for their invaluable feedback and support. This work was supported in part through Uchicago's AI Cluster resources, services, and staff expertise. This work was also partially supported by the NSF under Grant No. 2241303, and a gift from Google Research.
BibTeX
@inproceedings{zhang2024tedi,
title={TEDi: Temporally-Entangled Diffusion for Long-Term Motion Synthesis},
author={Zihan Zhang and Richard Liu and Kfir Aberman and Rana Hanocka},
year={2024},
booktitle={SIGGRAPH, Technical Papers},
doi={10.1145/3641519.3657515}
}