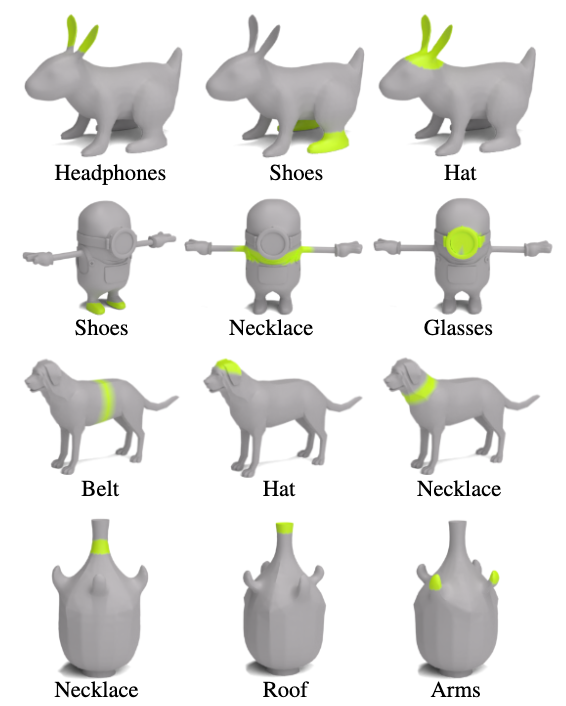
Headphones
Necklace
Arms
Poncho
Belt
Necklace
Hat
Hair
We present 3D Highlighter, a technique for localizing semantic regions on a mesh using text as input. A key feature of our system is the ability to interpret “out-of-domain” localizations. Our system demonstrates the ability to reason about where to place non-obviously related concepts on an input 3D shape, such as adding clothing to a bare 3D animal model. Our method contextualizes the text description using a neural field and colors the corresponding region of the shape using a probability-weighted blend. Our neural optimization is guided by a pre-trained CLIP encoder, which bypasses the need for any 3D datasets or 3D annotations. Thus, 3D Highlighter is highly flexible, general, and capable of producing localizations on a myriad of input shapes.

The Neural Highlighter maps each point on the input mesh to a probability. The mesh is colored using a probability-weighted blend and then rendered from multiple views. The neural highlighter weights are guided by the similarity between the CLIP embeddings of the 2D augmented images and the input text.
3D Highlighter is able localize different text-specified regions on the same mesh. Our framework demonstrates the nuanced understanding required to disambiguate similar, yet distinct target text specifications such as headphones and hat on the rabbit. Additionally, our method demonstrates global semantic understanding by correctly localizing regions such as the belt and necklace on the dog which have nearly identical geometry in the localization region.
3D Highlighter can be used to achieve localized stylization of meshes. Once we localize a region with our method, we can apply a predefined color and texture to only that region.

The styles used in the above image are Brick (left), Colorful Crochet (middle), Cactus (right).
We can also compute the localization of multiple regions and use those localizations to composite different styles together on a single mesh.

Given three different stylizations of the same object (Iron Man, Steve Jobs, and Yeti), we use 3D Highlighter to select different regions and combine them together (Ours).
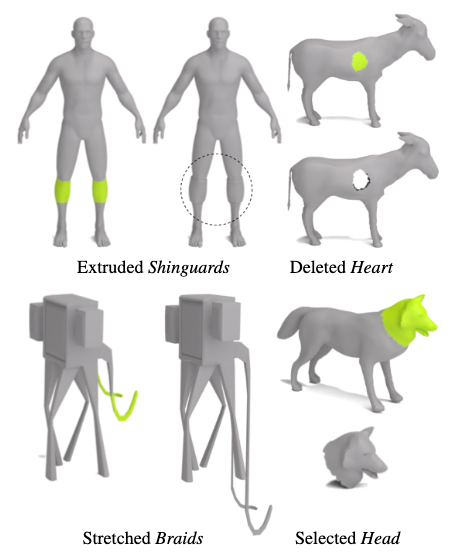
In addtion to stylization, 3D Highlighter can be used to perform geometric edits. Once we have localized a region, we can manipulate the geometry of the mesh with operations such as extrusion, stretching, deletion, and selection.
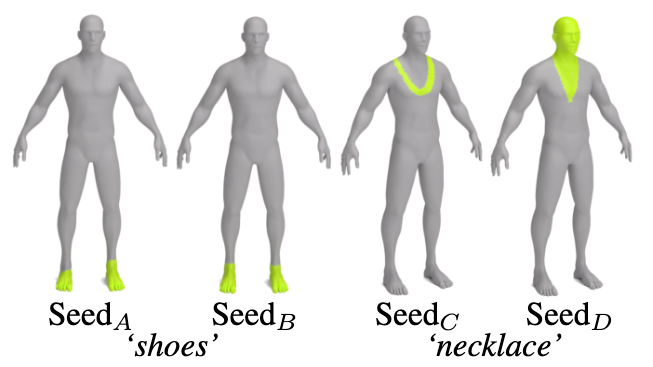
The strength of the supervision signal can vary for different mesh and prompt combinations. In cases where the signal is strong, non-determinism has little to no impact and the optimization produces nearly identical results every run. However, when the supervision signal is weaker, the optimization is more sensitive to non-determinism and we see that the highlighted regions can differ significantly between runs. For example, when applied to this human mesh, 3D Highlighter is robust to different seeds when using the target prompt shoes (left); while the target prompt necklace produces more variable results (right).
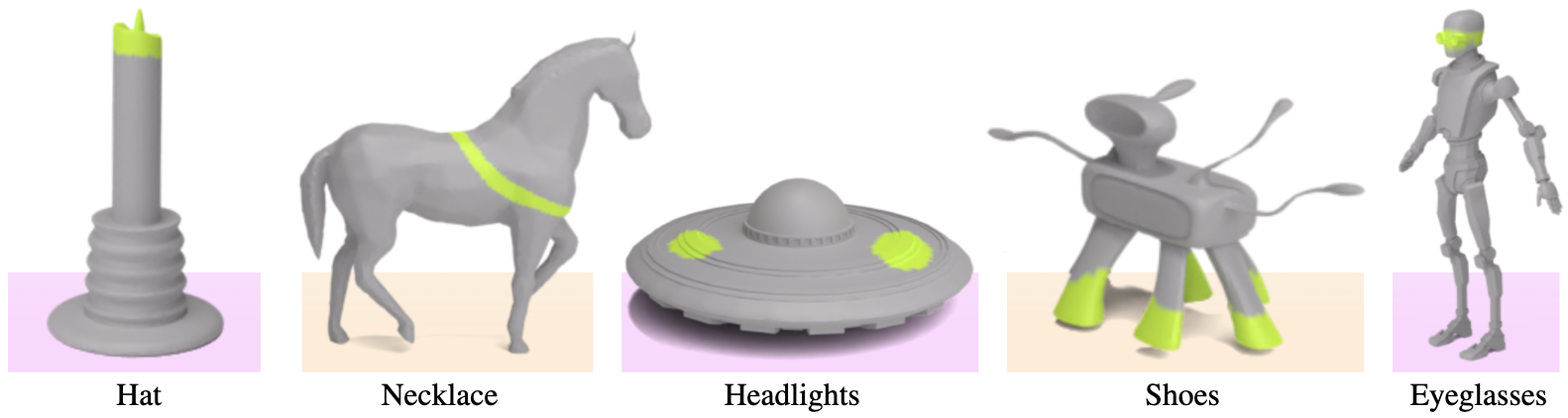
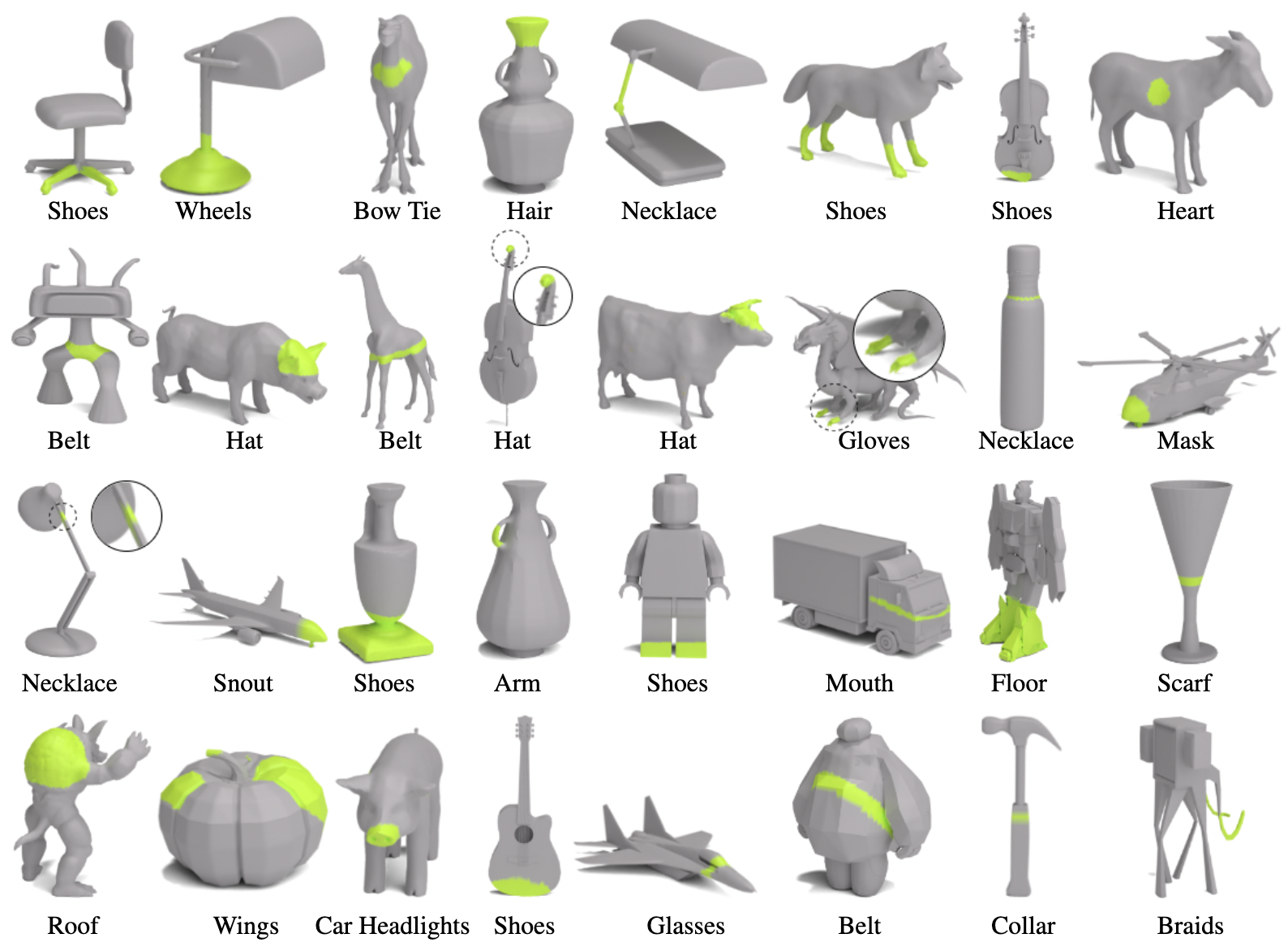
We present a gallery of results with additional mesh and prompt combinations.
@inproceedings{decatur2023highlighter,
title={3d highlighter: Localizing regions on 3d shapes via text descriptions},
author={Decatur, Dale and Lang, Itai and Hanocka, Rana},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={20930--20939},
year={2023}
}